Text Classification — CNN with LSTM
Introduction
Emails, chat exchanges, webpages, and social media all contain unstructured content. However, obtaining value from this data is a challenge unless it is structured in a certain way. It used to be a laborious and costly procedure since it needed time and resources to manually analyze the data. Text classifiers utilizing NLP have proved to be an excellent choice for quickly, cost-effectively, and scalable text data structure.
What is Text Classification?
The technique of categorizing text into structured groupings is known as text classification, alternatively known as text tagging or text categorization. Text classifiers can automatically evaluate text and assign a set of pre-defined tags or categories depending on its content using Natural Language Processing (NLP).
Some examples of Text Classification
Since it makes it easier to gain insights from data and automate operations inside an organization, text classification is becoming increasingly crucial to industries. Some of the most popular examples and use cases for automated text classification include:
- Sentiment Analysis: Analysis of a particular text to determine if it expresses good or negative feelings towards the topic at hand (e.g. for brand monitoring purposes).
- Topic Detection: Finding a topic of a line of text (e.g. to know if a product review is about Ease of Use, Customer Support, or Pricing when analyzing customer feedback).
- Language Detection: It is the process to determine the language of a text (e.g. know if an incoming support ticket is written in English or Local language for directing the tickets to the appropriate team).
Understanding the models
Convolutional Neural Network
A neural network in which at least one layer is a convolutional layer. A typical convolutional neural network consists of some combination of the following layers:
- convolutional layers
- pooling layers
- dense layers
Convolutional neural networks have had great success in certain kinds of problems, such as image recognition and text classification.
Recurrent Neural Network
A neural network that is intentionally run multiple times, where parts of each run feed into the next run. Specifically, hidden layers from the previous run provide part of the input to the same hidden layer in the next run. Recurrent neural networks are particularly useful for evaluating sequences so that the hidden layers can learn from previous runs of the neural network on earlier parts of the sequence.
For example, the following figure shows a recurrent neural network that runs four times. Notice that the values learned in the hidden layers from the first run become part of the input to the same hidden layers in the second run. Similarly, the values learned in the hidden layer on the second run become part of the input to the same hidden layer in the third run. In this way, the recurrent neural network gradually trains and predicts the meaning of the entire sequence rather than just the meaning of individual words.

Long Short-Term Memory (LSTM)
A type of cell in a recurrent neural network is used to process sequences of data in applications such as handwriting recognition, machine translation, and image captioning. LSTMs address the vanishing gradient problem that occurs when training RNNs due to long data sequences by maintaining history in an internal memory state based on new input and context from previous cells in the RNN.
A sample problem we are trying to solve
IMDB movie review sentiment classification problem. Each movie review is a variable sequence of words and the sentiment of each movie review must be classified. The IMDB Movie Review Dataset contains 25,000 highly-polar movie reviews (good or bad) for training and the same amount again for testing. The problem is to determine whether a given movie review has a positive or negative sentiment. Keras provides access to the IMDB dataset built-in. The imdb.load_data() function allows you to load the dataset in a format that is ready for use in neural networks and deep learning models. The words have been replaced by integers that indicate the ordered frequency of each word in the dataset. The sentences in each review are therefore comprised of a sequence of integers.
Why this approach?
CNN's are generally used in computer vision, however, they’ve recently been applied to various NLP tasks and the results were promising. Let’s briefly see what happens when we use CNN on text data through a diagram. The result of each convolution will fire when a special pattern is detected. By varying the size of the kernels and concatenating their outputs, you’re allowing yourself to detect patterns of multiples sizes (2, 3, or 5 adjacent words). Patterns could be expressions (word ngrams?) like “I hate”, “very good” and therefore CNNs can identify them in the sentence regardless of their position. Recurrent neural networks can obtain context information but the order of words will lead to bias; the text analysis method based on Convolutional neural network (CNN) can obtain important features of text through pooling but it is difficult to obtain contextual information which can be leverage using LSTM. So using the combination of CNN with LSTM could give us some interesting results
Developing a text classification model based on CNN + LSTM in Keras.
Let’s train two Text classification:
- LSTM based Text Classification
- CNN + LSTM based Text Classification
After training the two different classifications, you have to compare the accuracy on both of the models trained and report the best accuracy for which of them.
import numpy as np
from sklearn.model_selection import train_test_split
from keras.datasets import imdb
#import the required library
# Student will have to code here
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense,MaxPooling1D
from keras.layers import LSTM, Flatten, Dropout, Conv1D
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')# load the dataset but only keep the top n words, zero the rest
top_words = 10000
import numpy as np
np.load.__defaults__=(None, True, True, 'ASCII')
# call load_data with allow_pickle implicitly set to true
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=10000)
X_train,X_cv,y_train,y_cv = train_test_split(X_train,y_train,test_size = 0.2)
print("Shape of train data:", X_train.shape)
print("Shape of Test data:", X_test.shape)
print("Shape of CV data:", X_cv.shape)
# truncate and pad input sequences
max_review_length = 600
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
X_cv = sequence.pad_sequences(X_cv,maxlen=max_review_length)Shape of train data: (20000,)
Shape of Test data: (25000,)
Shape of CV data: (5000,)y_train[0:5]array([0, 0, 0, 0, 1], dtype=int64)# Decoding the data coded data of IMDB ( Data Understanding )
index = imdb.get_word_index()
reverse_index = dict([(value, key) for (key, value) in index.items()])
decoded = " ".join( [reverse_index.get(i - 3, "#") for i in X_train[0]] )
print(decoded)# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # notice i have given this 1 star if the option been given i would have given this zero as i put this dvd into my tv and sat down on my couch i was expecting some of the worst film making at its finest i looked this movie up on imdb and saw that it was the worst rated movie so i guess i came into it critical of every mistake but it didn't prepare me for the crap that was about to # from my television screen br br the box makes this movie out to look # ok at best do not let that fool you this movie needs to be banned from all shelves around the world br br the best way i can describe this movie is like porn but without any sex scenes in it the acting if you can call it that the plot so many holes must look like swiss cheese and the special effects really are just terrible br br please do not be like me and rent this movie because you think it will be funny to watch br br in the end i'm not saying i can make a better movie than this but i am thinking it# Architecture Diagram for LSTM Based Classifcation but you will have to change the
# configuration/model parameters while implementing it depending on the input , output and the
# Problem statement.
from IPython.display import Image
Image(filename='LSTM_model.png')
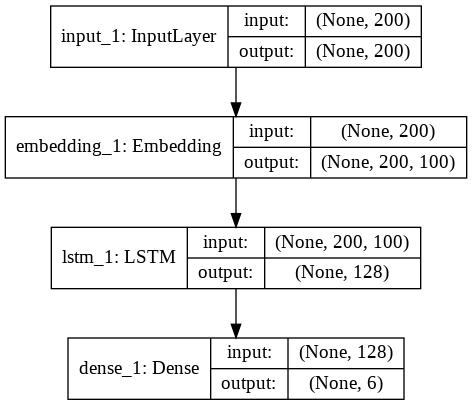
import tensorflow as tf
# Write the code for LSTM Based Classifcation
# Embedding layer
# LSTM Layer : You are free to choose the hyperparameters and the number of layers
# Dense Layer
# Students will be starting their code from here:
embedding_vector_length = 32
model = Sequential()
model.add(Embedding(input_dim=top_words, output_dim=embedding_vector_length, input_length=max_review_length))
model.add(LSTM(100))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
# Change the number of epochs and the batch size depending on the RAM Size
history = model.fit(X_train, y_train, epochs=5, batch_size=64,verbose = 1,validation_data=(X_cv,y_cv))Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 600, 32) 320000
_________________________________________________________________
lstm (LSTM) (None, 100) 53200
_________________________________________________________________
dense (Dense) (None, 1) 101
=================================================================
Total params: 373,301
Trainable params: 373,301
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/5
313/313 [==============================] - 402s 1s/step - loss: 0.6111 - accuracy: 0.6496 - val_loss: 0.3238 - val_accuracy: 0.8664
Epoch 2/5
313/313 [==============================] - 281s 896ms/step - loss: 0.2821 - accuracy: 0.8886 - val_loss: 0.3057 - val_accuracy: 0.8686
Epoch 3/5
313/313 [==============================] - 276s 881ms/step - loss: 0.2089 - accuracy: 0.9235 - val_loss: 0.3352 - val_accuracy: 0.8642
Epoch 4/5
313/313 [==============================] - 272s 868ms/step - loss: 0.1593 - accuracy: 0.9450 - val_loss: 0.4313 - val_accuracy: 0.8548
Epoch 5/5
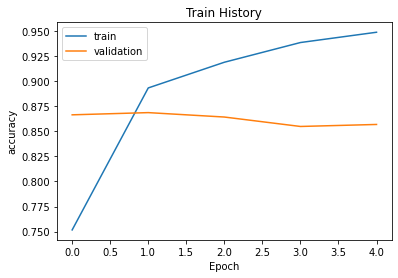
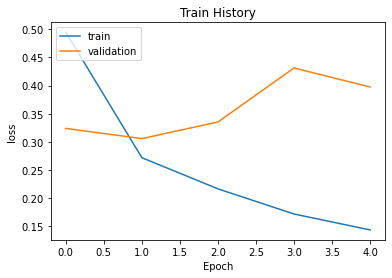
313/313 [==============================] - 274s 876ms/step - loss: 0.1312 - accuracy: 0.9537 - val_loss: 0.3974 - val_accuracy: 0.8568def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(history,'accuracy','val_accuracy')
show_train_history(history,'loss','val_loss')
print('Training loss \t', history.history['loss'][-1]*100)
print('Training accuracy ', history.history['accuracy'][-1]*100)
print('Validation loss ', history.history['val_loss'][-1]*100)
print('Validation accuracy ', history.history['val_accuracy'][-1]*100)Training loss 14.32565450668335
Training accuracy 94.87000107765198
Validation loss 39.74485695362091
Validation accuracy 85.68000197410583# Final evaluation of the model using test dataset
# Students will be starting their code from here:
scores = model.evaluate(X_test, y_test, verbose=1)
print('Testing loss \t', scores[0]*100)
print('Testing accuracy ', scores[1]*100)782/782 [==============================] - 70s 89ms/step - loss: 0.3974 - accuracy: 0.8572
Testing loss 39.741843938827515
Testing accuracy 85.7159972190857predict=model.predict_classes(X_test)
predict_classes=predict.reshape(len(X_test))def get_original_text(i):
word_to_id = imdb.get_word_index()
word_to_id = {k:(v+3) for k,v in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
id_to_word = {value:key for key,value in word_to_id.items()}
return ' '.join(id_to_word[id] for id in X_test[i])SentimentDict={1:'positive', 0:'negative'}
def display_test_sentiment(i):
print(get_original_text(i))
print('label: ', SentimentDict[y_test[i]], ', prediction: ', SentimentDict[predict_classes[i]])
display_test_sentiment(3)<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <START> i generally love this type of movie however this time i found myself wanting to kick the screen since i can't do that i will just complain about it this was absolutely idiotic the things that happen with the dead kids are very cool but the alive people are absolute idiots i am a grown man pretty big and i can defend myself well however i would not do half the stuff the little girl does in this movie also the mother in this movie is reckless with her children to the point of neglect i wish i wasn't so angry about her and her actions because i would have otherwise enjoyed the flick what a number she was take my advise and fast forward through everything you see her do until the end also is anyone else getting sick of watching movies that are filmed so dark anymore one can hardly see what is being filmed as an audience we are <UNK> involved with the actions on the screen so then why the hell can't we have night vision
label: negative , prediction: positive# High Level Model Architecture
from IPython.display import Image
Image(filename='1_VGtBedNuZyX9E-07gnm2Yg.png')

# create the model
embedding_vector_length = 32
cnn_model = Sequential()
# Students will be starting their code from here:
# Write the code for LSTM Based Classifcation
# Embedding layer
# Convolution-1D Layer : You are free to choose the hyperparameters and the number of layers
# LSTM Layer : You are free to choose the hyperparameters and the number of layers
# Dense Layer
cnn_model.add(Embedding(input_dim=top_words, output_dim=embedding_vector_length, input_length=max_review_length))
cnn_model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
cnn_model.add(MaxPooling1D(pool_size=2))
cnn_model.add(LSTM(100))
cnn_model.add(Dense(units=1, activation='sigmoid'))
# Students will be ending their code here
cnn_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(cnn_model.summary())
# Change the number of epochs and the batch size depending on the RAM Size
history_c=cnn_model.fit(X_train, y_train, epochs=5, batch_size=64,verbose = 1,validation_data=(X_cv,y_cv))Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 600, 32) 320000
_________________________________________________________________
conv1d_1 (Conv1D) (None, 600, 32) 3104
_________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 300, 32) 0
_________________________________________________________________
lstm_1 (LSTM) (None, 100) 53200
_________________________________________________________________
dense_1 (Dense) (None, 1) 101
=================================================================
Total params: 376,405
Trainable params: 376,405
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/5
313/313 [==============================] - 125s 393ms/step - loss: 0.5673 - accuracy: 0.6678 - val_loss: 0.2863 - val_accuracy: 0.8810
Epoch 2/5
313/313 [==============================] - 122s 390ms/step - loss: 0.2290 - accuracy: 0.9146 - val_loss: 0.2874 - val_accuracy: 0.8792
Epoch 3/5
313/313 [==============================] - 125s 399ms/step - loss: 0.1450 - accuracy: 0.9524 - val_loss: 0.3463 - val_accuracy: 0.8698
Epoch 4/5
313/313 [==============================] - 120s 383ms/step - loss: 0.1000 - accuracy: 0.9669 - val_loss: 0.3341 - val_accuracy: 0.8810
Epoch 5/5
313/313 [==============================] - 122s 389ms/step - loss: 0.0676 - accuracy: 0.9801 - val_loss: 0.3809 - val_accuracy: 0.8786# Final evaluation of the CNN + RNN model using the test data
# Students will be starting their code from here:
show_train_history(history_c,'accuracy','val_accuracy')
show_train_history(history_c,'loss','val_loss')
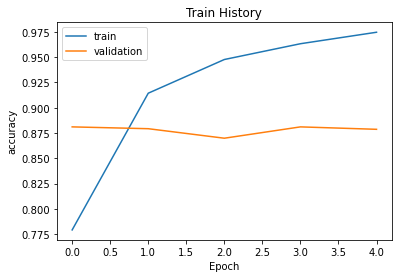
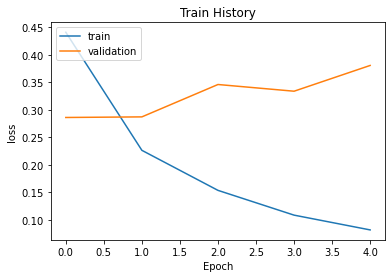
print('Training loss \t', history_c.history['loss'][-1]*100)
print('Training accuracy ', history_c.history['accuracy'][-1]*100)
print('Validation loss ', history_c.history['val_loss'][-1]*100)
print('Validation accuracy ', history_c.history['val_accuracy'][-1]*100)Training loss 8.179525285959244
Training accuracy 97.45500087738037
Validation loss 38.09112906455994
Validation accuracy 87.8600001335144# Final evaluation of the model using test dataset
# Students will be starting their code from here:
cnn_scores = cnn_model.evaluate(X_test, y_test, verbose=1)
print('Testing loss \t', scores[0]*100)
print('Testing accuracy ', scores[1]*100)782/782 [==============================] - 40s 51ms/step - loss: 0.4218 - accuracy: 0.8672
Testing loss 39.741843938827515
Testing accuracy 85.7159972190857
Comparing the models
#Creating a function to display values:
def show_values_on_bars(axs, h_v="v", space=0.2):
def _show_on_single_plot(ax):
if h_v == "v":
for p in ax.patches:
_x = p.get_x() + p.get_width() / 2
_y = p.get_y() + p.get_height()
value = "{:.2f}".format(p.get_height())
ax.text(_x, _y, value, ha="center")
elif h_v == "h":
for p in ax.patches:
_x = p.get_x() + p.get_width() + float(space)
_y = p.get_y() + p.get_height()
value = "{:.2f}".format(p.get_width())
ax.text(_x, _y, value, ha="left")
if isinstance(axs, np.ndarray):
for idx, ax in np.ndenumerate(axs):
_show_on_single_plot(ax)
else:
_show_on_single_plot(axs)#Creating a dataframe to draw out comparisons
import seaborn as sns
import pandas as pd
results=[]
results.append([scores[0], 'Loss', 'RNN'])
results.append([scores[1], 'Accuracy', 'RNN'])
results.append([cnn_scores[0], 'Loss', 'CNN+RNN'])
results.append([cnn_scores[1], 'Accuracy', 'CNN+RNN'])
comparison = pd.DataFrame(results, columns = ['Score', 'Metric', 'Model'])
plt.figure(figsize=(10,10))
plot = sns.barplot(x=comparison['Metric'],y=comparison['Score'], hue = comparison['Model'])
show_values_on_bars(plot)
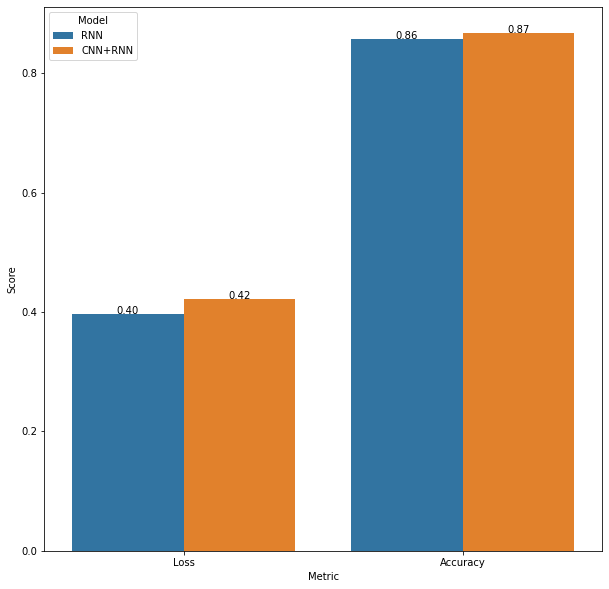
We see that there is no noticeable change in performance when we have added a convolutional layer to the RNN model.
Here is a link to the code used.
